
2024年
4月
17日
OrangePi5にZabbixをインストールする
OrangePi

ogochan
Orange Pi 5でAIの第6弾です。
今回はVALL-E-Xを試してみました。
VALL-E-Xは、Microsoftによって作られたTTS(text to speech)の実装です。
短い音声を元に、その話者の声を真似するという、とんでもない技術です。詳しいことは
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Speak Foreign Languages with Your Own Voice:Cross-Lingual Neural Codec Language Modeling
という元論文を読んで下さい。
短い音声から任意のしゃべりを作るわけなので、Chatrのような自動音素片抽出ではなく、声道構造を推測して合成するタイプの物真似技術です。
昔はChatrでもびっくりしたもので、同じ頃に声道構造を推測するタイプの音声合成作れないかなーとか考えていた身にすると、もうびっくりびっくりです。いわゆる音声信号処理とは違ったアプローチですから(使ってないわけではない)。
というのは置いておいて、この論文を元に作られたのが、ここで紹介しているソフトです。こちらも名前が「VALL-E-X」ってなっているので、ちょっと区別しにくいですね。
この辺のもののインストールは、それ自体は簡単です。だいたいpip一発という感じで特に難しいことはありません。つまづきがちなのはGPUを使うための諸々で、Orange Pi 5はまだそういったものを使えないので、何も悩みようがありません。
というわけですることは、
$ pip install -U pip setuptools
$ git clone https://github.com/Plachtaa/VALL-E-X.git
$ cd ~/VALL-E-X/
$ pip install -r requirements.txt
これだけです。
「これだけ」とか言ってしまったのですが、実際には結構手間がかかってまして、問題はSudachiPyのインストールに詰まってしまったことです。
あれこれ謎エラーが出て、Sudachiをインストールしてみたりしたのですが、結局のところ最初の1行にあるように、pipとsetuptoolsをアップデートしたらうまく入るようになりました。Sudachiはsudachi.rsとなっているんですね。
私はモタモタやっている時にRustをaptで入れちゃってますが、もしかしてpipを入れる時にRustがないと怒られるかも知れません。怒られたら素直に入れましょう。aptで入れます。
$ sudo apt install rustc
同じく書いてはないですが、ffmpegも必要なので入れておきましょう。aptで入れます。
$ sudo apt install ffmpegインストールそのものはこれだけです。
さて、インストールしたら起動するわけですが、なぜかドキュメントには起動のためのコマンドラインが書いてありません。
ソースやらファイル名やら見ていたら、どうやらlaunch-ui.pyというのを起動すれば良いらしいことを発見しました。
$ python launch-ui.py
default encoding is utf-8,file system encoding is utf-8
You are using Python version 3.10.12
Use 8 cpu cores for computing
100% [....................................................................] 1482302113 / 1482302113Downloading: "https://dl.fbaipublicfiles.com/encodec/v0/encodec_24khz-d7cc33bc.th" to /home/ogochan/.cache/torch/hub/checkpoints/encodec_24khz-d7cc33bc.th
100%|███████████████████████████████████████████████████████████████| 88.9M/88.9M [00:03<00:00, 25.6MB/s]
Downloading (…)lve/main/config.yaml: 100%|███████████████████████████████| 503/503 [00:00<00:00, 613kB/s]
Downloading pytorch_model.bin: 100%|████████████████████████████████| 40.4M/40.4M [00:01<00:00, 27.5MB/s]
100%|█████████████████████████████████████| 1.42G/1.42G [01:40<00:00, 15.3MiB/s]
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
なんか動いてくれましたね。最初はいろんなファイルをダウンロードするところから始まります。ファイル名を見る限りではモデルとかですね。
これでhttp://127.0.0.1:7860/につなぐとweb UIが動くはずなんですが、つながりません。
このweb UIはGradioを使って書かれているのですが、デフォルトでGradioが開くのはローカルだけなので外からつながりません(同じパソコンの上ならつながります)。そこで、
$ GRADIO_SERVER_NAME=10.1.252.34 python launch-ui.pyのようにしてやると、外からつながるインターフェイスで開いてくれます。
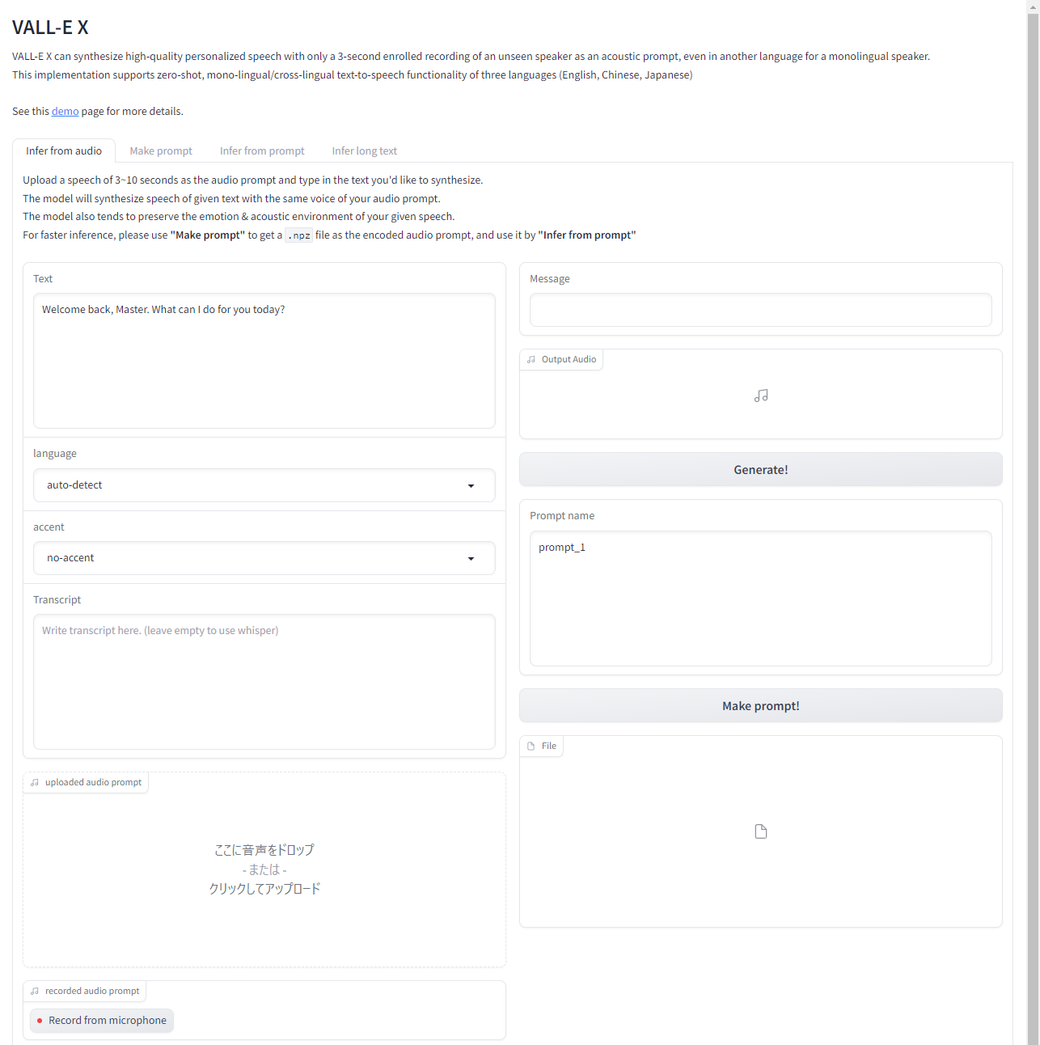
ブラウザでhttp://10.1.252.34:7860/につないでやると、web UIが表示されます。
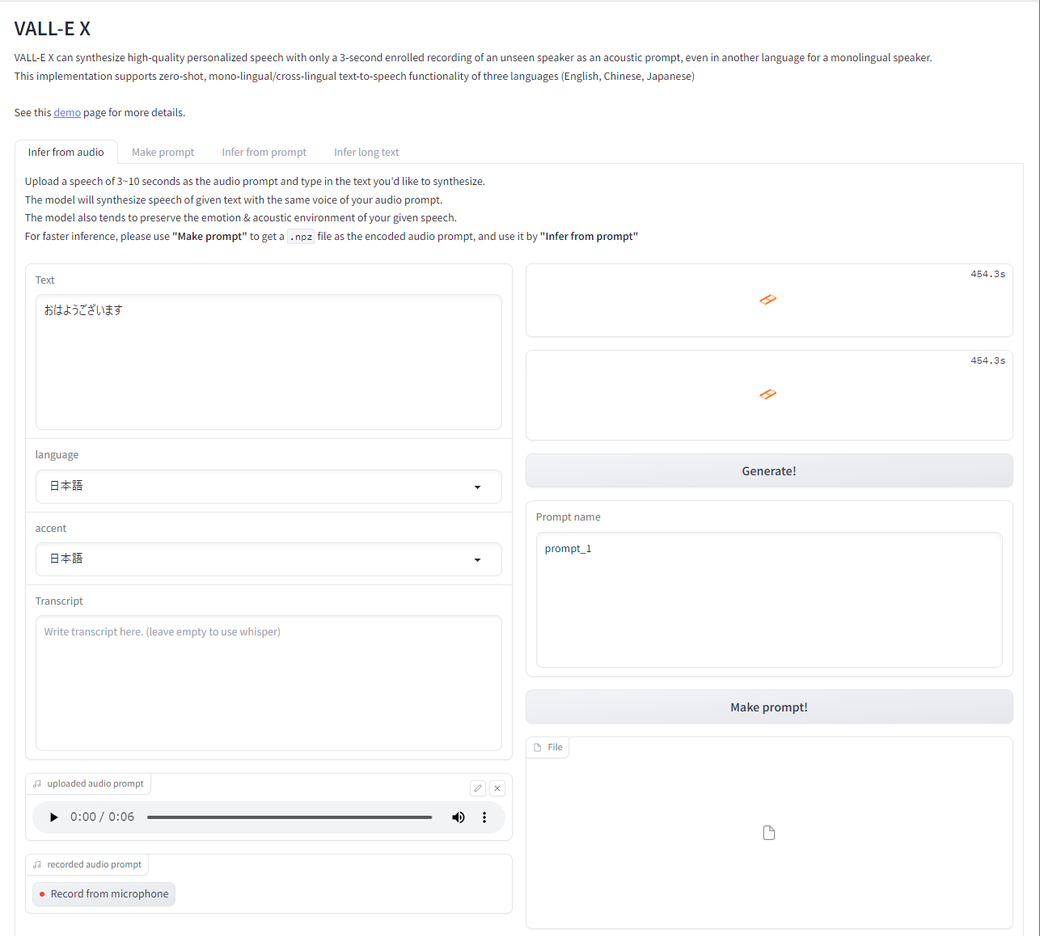
必要なところに必要なものを入れると動いてくれます。
とりあえずこんな感じで入れてみました。
試しに使った元音声ファイルは「つくよみちゃん」です。
つくよみちゃんコーパス│声優統計コーパス(JVSコーパス準拠)
こういったのが公開されているのは嬉しいですね。
web UIのうち、Transcriptと書かれているところは、本来元音声が何をしゃべっているか書くのですが、入れないと勝手にwhisperを使って音声認識してくれるようです。
Textと書かれているところに、合成したいテキストを入れてGenerate!ボタンを押すと生成してくれます。
ちなみに、「おはようございます」を合成するのにOrange Pi 5で20分ほどかかりました。合成された音声は2秒ほどですけど。ざっとリアルタイムの600倍くらいかかりますね。ちなみに、処理時間の20分のうち11分程度が前処理(モデル読み込みとかも含む)、残りが合成のようです(あくまで目安です)。
合成された音声については、びっくりするに値する程度にはちゃんとしています。理屈がわかっていても手品のようです。
という感じで、Orange Pi 5でもVALL-E-Xは動いてくれました。生成される音声のクオリティは手品を見ているようです。
では実用になるかと言えば、ちょっと処理時間がかかり過ぎて、そのままどうこうするには難しいですね。リアルタイムの600倍もかかるので、実用となると頭抱えてしまいます。まぁ、生成する音声が長くなれば「600倍」ももうちょっとマシにはなると思いますけど。
とは言え、あまり急いでない「できていれば十分」程度のものであれば、品質の良さもあって実用として使えないこともないなという感じです。